本文共 1339 字,大约阅读时间需要 4 分钟。
作为核心驱动的研究:研究环境
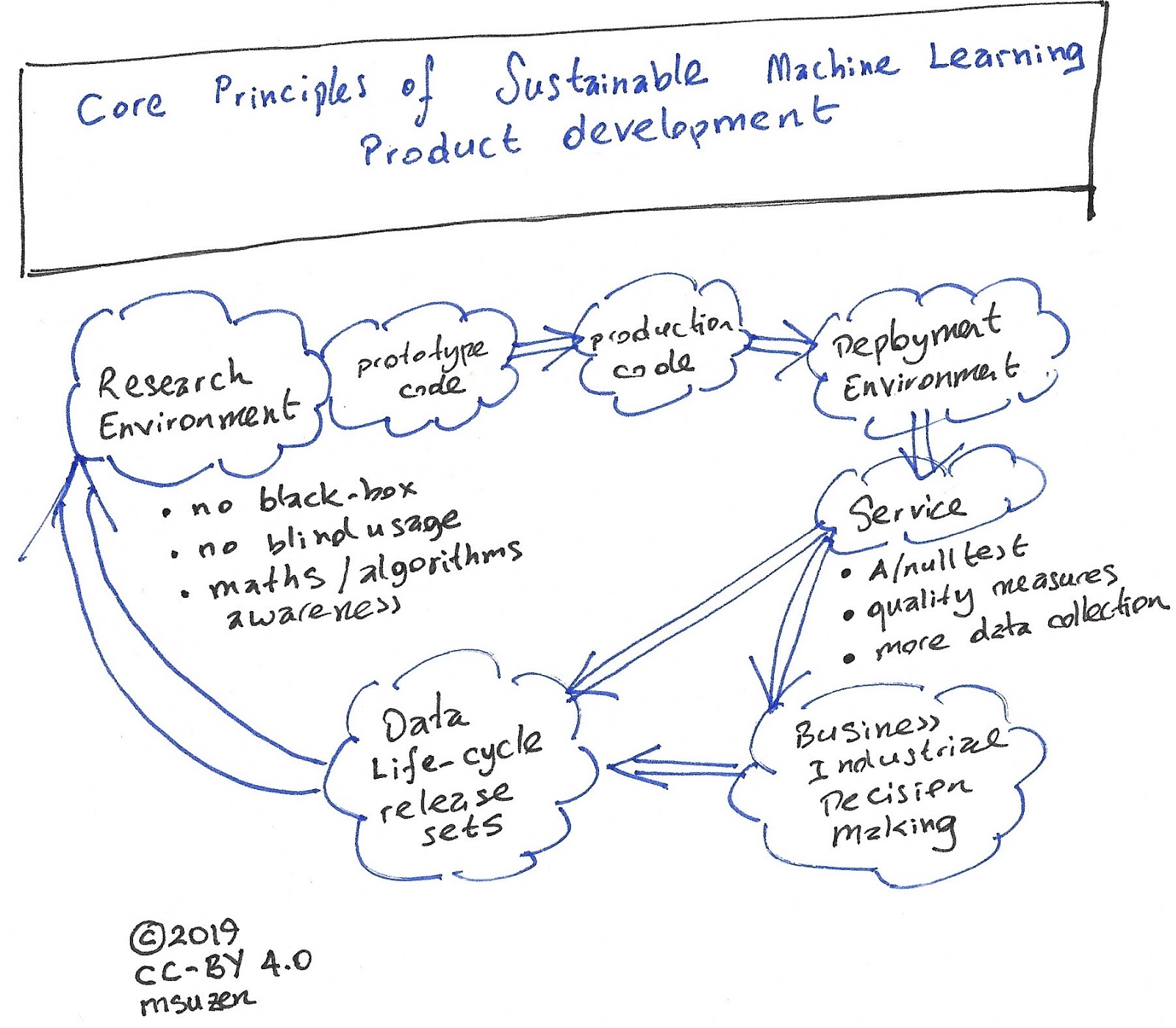
不管你的组织规模如何,只要你正在开发机器学习或人工智能产品,那么你的核心资产就是研究专业人员、数据科学家或人工智能科学家,无论他们的学术背景如何。盲目地使用软件库开发模型并不能解决产品部署后可能遇到的问题。比如,即使你需要进行简单的超参数搜索,这也很容易最后被迫让位于研究。为什么会这样呢?因为很可能没有人尝试过使用你的数据集构建模型或者尝试过建模任务,你可能需要一种新的方法,与机器学习库提供的方法不同。从机器学习库的最简单的不同角度或偏差就可以产生一个研究问题。
- 没有完整的“黑匣子”的方法。
- 不要盲目使用软件库。
- 具备数学和算法方面的知识和技能。
将研究代码和生产代码分开
软件开发是机器学习产品开发不可或缺的一部分。然而在研究过程中,代码开发可能会变得问题多多,而科学家,即使是非常优秀的软件开发人员,最终也会编写出难以理解的槽糕代码。如果对结果的再现性和健壮性有信心的话,产品代码就应该用高质量的软件工程原则重新编写。
数据标准化:发布用于研究的数据集
机器学习产品的一个冷启动问题是,在进行任何类似的研究工作之前就发布和设计数据集。当然,这必须与行业需求保持一致。想象一下用于基准测试的数据集,比如MINST或imagenet。发布的数据集将是任何模型构建或产品开发的第一步,并将构成数据产品本身。数据版本控制也是必须的。
不要痴迷工作流:所有的工作流都是特别的
没有所谓的普遍或通用的工作流。工作流取决于人们对流程和步骤的理解。人类的理解是基于语言的基础上,而在语言学上,并没有所谓的通用语言,至少通用语法还不实用。对研究步骤来说,宽松定义的步骤就足够了。然而,一旦投入生产,那么可能就需要更为严格的工作流设计,但是要注意,所有的工作流都是特别的。
不要为核心数据科学进行敏捷迭代
敏捷软件开发适用于软件开发创新。Sprint(敏捷迭代)或Agile(敏捷开发)并不适用于人工智能研究环境,因为它是一种不同于软件工程的创新。如果认为敏捷开发是进行科学创新的一种方法,那就是天真的一厢情愿了。通过演示和详细的技术报告来构建研究小组,定期审查并发布成果,这种形式更适合在小型研讨会上进行数据科学研究。还可以提出一个简单的提案来决定投资方向,类似于研究提案。
反馈:服务到业务决策再到研究
使用机器学习技术的服务应该会产生更多的数据。第一个服务监控是A/Null测试,这意味着在没有人工智能产品的情况下会发生什么。对服务数据的详细分析将为业务和研究带来更多的洞见。
- 产生影响评估:A/Null测试
- 服务质量:服务质量基本上可以根据机器学习模型的成功程度来衡量,这必须是技术性的。
结论和展望
须知天下没有免费的午餐,开发人工智能产品这样的事情并不会很快就会实现完全的自动化。诚然,工具可以极大地提高生产力,但是想要人工智能取代数据科学家或人工智能科学家远非现实,至少目前如此。如果你正在人工智能产品上投资,那么,基本上可以说你就是在核心研究方面进行投资,忽略重要的这一点的话,可能会让你的组织为此付出高昂的代价。它们的基本核心原则或者变化有可能有助于维持人工智能产品更长时间,并形成相应的团队。
原文链接:
转载地址:http://rbdox.baihongyu.com/